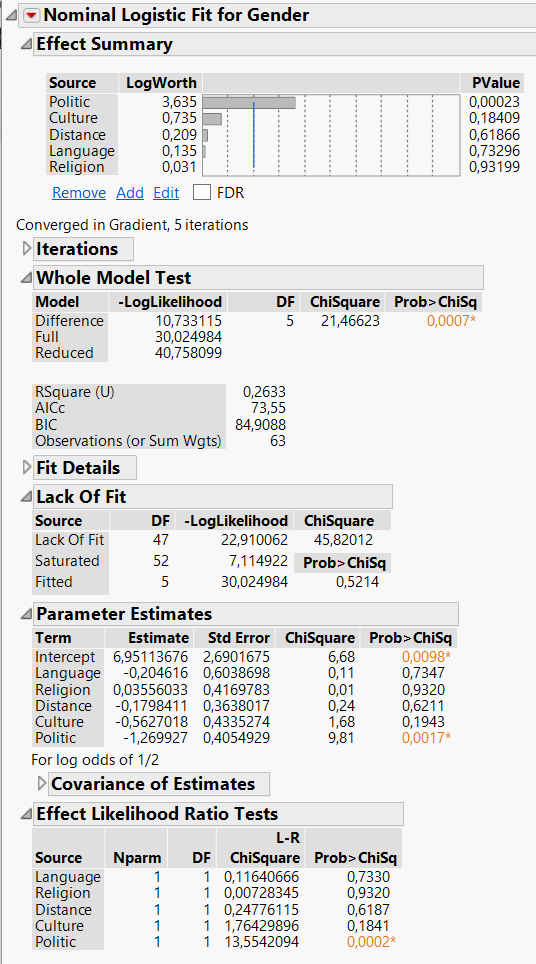
Du har lavet en model, som forsøger at estimere en forventet værdi for "Tilbøjelighed til at flytte til udlandet" hos en tilfældig respondent, afhængigt af hvad denne person svarer til dine fem underspørgsmål om henholdsvis sprog, religion, distance, kultur og politik.
Estimat-værdien -1,26 betyder at den samlede funktion for "Tilbøjelighed til at flytte til udlanet", som måles på en talskala, f.eks. mellem 1 og 10, falder med -1,26 * Den værdi en respondent svarer for "Politik"-spørgsmålet (Som f.eks. kan være formuleret noget a la "Hvor meget går du op i dansk politik på en skala fra 1-10?)
Dvs. har en person i dit tilfældet svaret på de fem spørgsmål med værdierne:
Sprog 3
religion 9
distance 4
kultur 5
politik 2
Får denne person en forventet tilbøjelighed til at flytte på 6,9 -0,02*3 + 0,03 * 9 og så videre.... = 5,64 f.eks. (har ikke regnet efter, men du forstår pointen).
MEN
Modellen er slet ikke færdig endnu, så du kan ikke bruge værdien -1,26. Dette skyldes at Probability for fire af dine varibale er større end 0,5, hvilket betyder at de ikke bidrager signifikant til at forklare variansen i Y (Tilbøjelighed). På godt dansk: Der kan ikke bevises en tydelig sammenhæng mellem disse parametre (sprog, kultur, distance og religion) og så dit Y. Derfor skal du fjerne dét parameter som har den dårligste p-værdi ( religion med 0,9320) og køre analysen igen. Hvis du stadig - hvilket du helt sikkert vil have - har parametre med en p-værdi over 0,05, skal du fjerne parametre indtil ALLE tilbageværende parametre er "signifikante" (p-værdi under 0,05)... SÅ har du en model, som kan bruges til at forudsige noget som helst :)
Held og lykke :)